从容器云到智能云
在 AI 智能体(Agent)系统快速发展的今天,单个智能体已经不够用了。我们需要的是多智能体协作、可观测执行轨迹、安全副作用治理,以及在分布式环境下的可靠调度。
OpenClaw 在 gateway、tools、sessions 和本地多智能体路由上表现出色,但面对大规模协作、跨节点调度和操作者可见性时仍有短板。而类似 golutra 的编排与 trace 能力,又提供了宝贵的补充。
本文提出一个演进架构:将 Kubernetes 作为坚实底座,在其之上构建一个专为 AI 设计的控制平面——我们称之为 Kubernetes AI OS。它不替代 Kubernetes,而是将其视为基础设施层,新增智能体运行时、执行调度、能力发现、副作用治理和跨节点协同等能力。
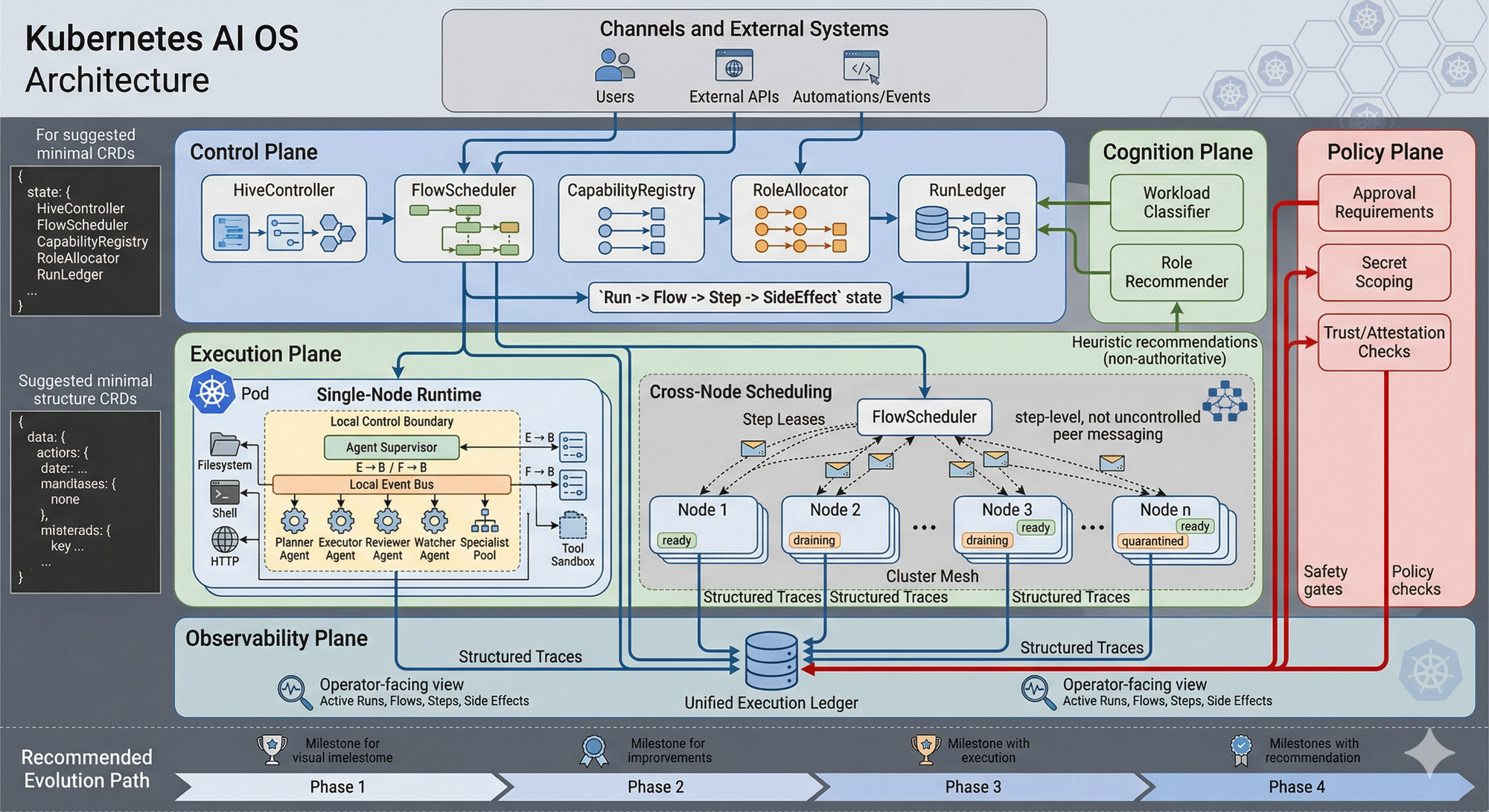
Kubernetes AI OS:让 Kubernetes 成为 AI 智能体的原生控制平面
在 AI 多智能体系统越来越复杂的今天,单节点运行时已经不够。我们需要一个能支持协作、可观测、安全调度,并且真正面向操作者的执行系统。
基于 OpenClaw 的 gateway runtime,我提出一个演进方向:在 Kubernetes 之上构建一个 AI 控制平面,称为 Kubernetes AI OS。
它不替代 Kubernetes,而是把 Kubernetes 当作坚实的底座,新增专为 AI 设计的智能体运行时、执行调度、副作用治理和跨节点协同能力。
为什么需要这个架构?
OpenClaw 目前在 channels、tools、sessions 和本地多智能体路由上很强,但在大规模协作、执行轨迹审计、跨节点放置上还有明显短板。
我们希望融合:
- OpenClaw 的南向集成和 agent runtime
- 类 golutra 的执行轨迹与可视化能力
- Kubernetes 的生命周期、调度和故障恢复能力
核心理念只有一句话:执行必须可见、可检查、可归因。没有清晰的执行账本,多智能体系统很容易变成黑盒。
设计目标
- 支持单节点内多智能体清晰协作
- 支持跨节点的工作流级调度
- 节点可自动加入、隔离、恢复
- 用小模型辅助角色推荐,但高风险决策必须走策略面
- 所有有意义的动作都要进统一执行账本
- 清晰分离控制面、执行面、可观测面和策略面
不做的事:不替换 Kubernetes 原生调度,不允许智能体无限制自由聊天,不让模型直接决定提权或拓扑变更等高危操作。
六层架构概览
系统分为六层,责任边界清晰:
- Southbound Gateway Layer:沿用 OpenClaw 的 channel、tool、session 接入能力
- Execution Kernel:核心执行层,管理 Run → Flow → Step → SideEffect 全生命周期
- Cluster Mesh:负责节点注册、能力发布、step 调度和安全隔离(不鼓励节点间自由聊天)
- Observability Plane:统一执行账本,提供 runs、flows、steps、side effects 的可视化视图
- Cognition Plane:用小模型做 workload 识别、角色推荐、状态总结
- Policy Plane:负责安全审批、secret 作用域、side-effect 治理和信任检查
控制面决定“什么该跑、在哪跑、按什么策略跑”;执行面负责真正执行并产生 trace。
单节点多智能体运行时
即使只有一个节点,也要支持多角色协同运行。推荐基础角色包括:
- Planner(规划)
- Executor(执行)
- Reviewer(审查)
- Watcher(监控)
- Specialist(领域专家)
所有动作先上报本地 ledger,再由控制面聚合,确保执行轨迹清晰可见。
跨节点调度:基于 Step 而非聊天
跨节点协作的关键是以 Step 为单位调度,而不是让节点间随意转发消息。这样才能保证所有权清晰、可取消、可审计。
调度器会综合考虑所需工具、模型可用性、硬件资源、locality、信任等级和 tenant 亲和性等因素。
节点状态包括 joining、ready、degraded、quarantined、draining 等,支持自动隔离高风险节点。
核心原语:Execution Ledger(执行账本)
这是整个系统最重要的一环。所有事件(run、flow、step、side effect、policy 等)都绑定到 runId,形成统一可查询的账本。
操作者应该能轻松回答:
- 是哪个 agent 在执行?
- 发生了哪些副作用?
- 当前卡在哪一步?
- 这个失败是否可以安全重试?
与 Kubernetes 的关系
Kubernetes 继续负责 Pod 调度、liveness、service discovery、存储和 RBAC 等基础设施能力。
AI OS 层则通过 CustomResource(CRD)来表达 HiveRun、HiveFlow、HiveStepLease、HiveNode 等对象,用 Operator 实现调谐逻辑。
演进路径建议
推荐从小步开始:
- Phase 1:单节点补齐 run ledger、flow graph 和 side-effect 可视化
- Phase 2:实现单集群 step scheduler 和节点管理
- Phase 3:加入轻量角色推荐
- Phase 4:实现自适应集群行为
第一目标不是追求完全自治,而是先做一个单节点、具备一流可观测能力的 AI 运行时。先让执行可见,再让副作用可治理,最后再做跨节点调度。
Kubernetes AI OS 的目标,是让 Kubernetes 真正成为 AI 时代的操作系统底座:在保持安全和可控的前提下,充分发挥多智能体的协作能力。