Flink 理解
前言
在大数据系统的发展过程中,一直存在一个核心问题:
数据越来越多,但处理速度越来越慢。
传统的数据处理方式,大多数是 离线处理。
例如:
每天晚上跑一次任务:
- 统计用户行为
- 计算广告数据
- 生成报表
- 分析业务指标
这种方式叫:
Batch Processing(批处理)
典型工具例如:
- Hadoop MapReduce
- Hive
- Spark
这些系统适合处理 海量历史数据。
但是随着互联网的发展,很多业务开始需要:
实时数据处理。
例如:
- 实时风控
- 实时推荐
- 实时监控
- 实时广告竞价
- 实时日志分析
这些场景有一个共同特点:
数据必须“边产生边处理”。
不能等到第二天。
于是就出现了一个新的计算模式:
Stream Processing(流式计算)。
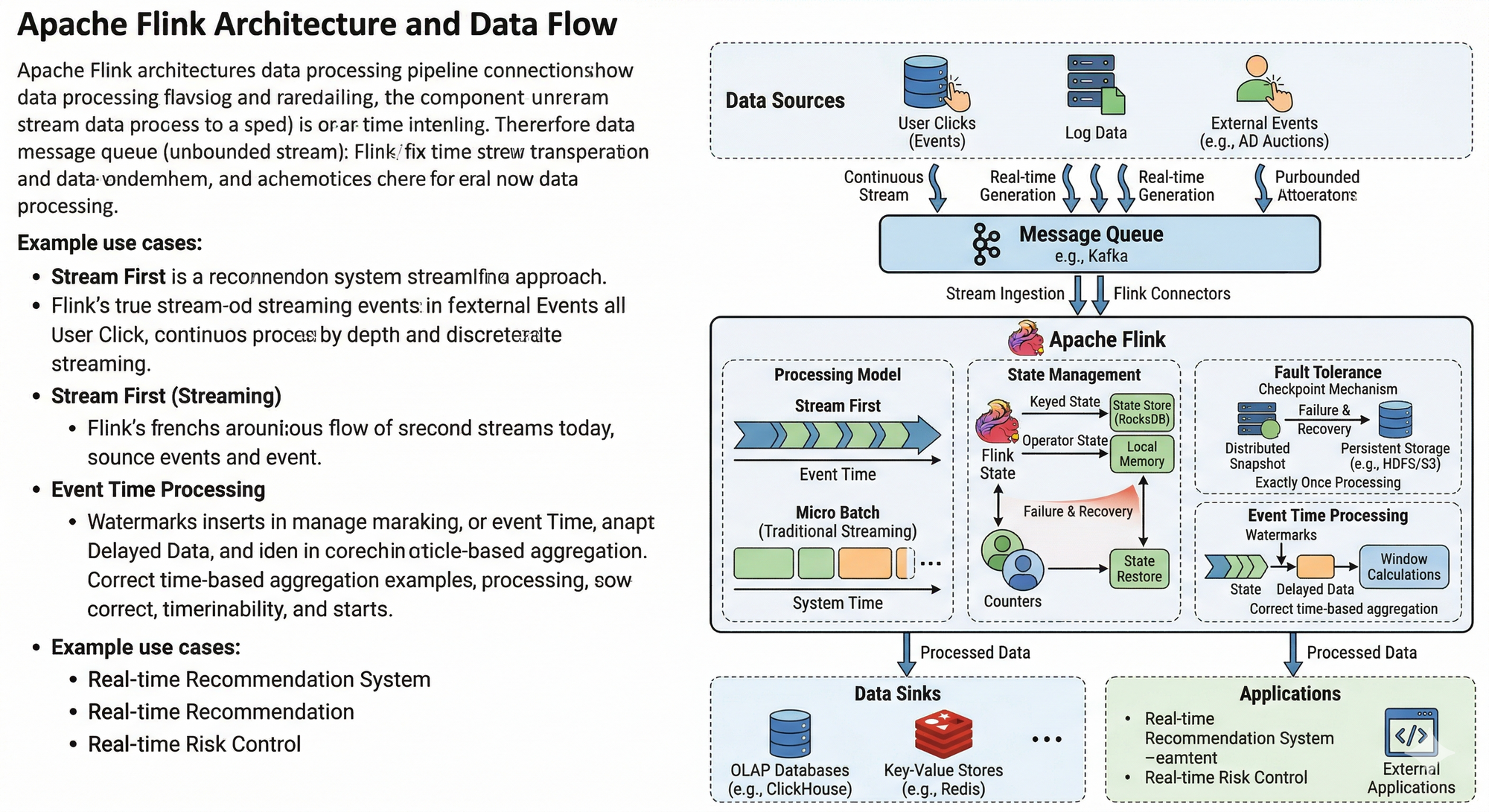
为什么需要 Flink
早期实时计算系统主要依赖:
- Storm
- Spark Streaming
但这些系统都有一些问题。
例如:
Storm 虽然是流计算系统,但:
- 开发复杂
- 容错能力一般
- 状态管理困难
Spark Streaming 虽然稳定,但它的本质是:
微批处理(Micro Batch)。
也就是说:
它并不是真正的流计算。
例如:
每1秒处理一批数据这种模式在很多场景下仍然不够实时。
于是 Flink 出现了。
Flink 的目标很明确:
构建一个真正的流计算系统。
Flink 解决了什么问题
Flink 的出现,主要解决了几个关键问题。
1 实时数据处理
Flink 可以实现真正的 毫秒级实时计算。
例如:
用户点击商品:
点击 → Kafka → Flink → 实时推荐整个过程可能只需要:
几十毫秒。
状态管理问题
在流计算中,一个非常重要的问题是:
状态(State)。
例如:
统计用户点击次数:
用户A 点击 1次
用户A 点击 2次
用户A 点击 3次系统需要记住之前的数据。
Flink 内置了 状态管理机制:
- Keyed State
- Operator State
并且支持:
- 本地状态
- RocksDB 状态存储
这样可以处理 超大规模状态数据。
容错问题
在分布式系统中,节点宕机是常态。
Flink 通过 Checkpoint 机制 来保证数据安全。
简单来说:
系统会定期保存计算状态。
如果节点宕机:
系统可以从 Checkpoint 恢复计算。
这种机制保证了:
Exactly Once(精准一次处理)。
也就是说:
每条数据只会被处理一次。
事件时间问题
在流计算中,有一个非常难的问题:
事件时间(Event Time)。
例如:
日志数据可能会延迟到达。
如果只按系统时间计算,就会出现统计错误。
Flink 引入了:
Watermark(水位线)机制。
Watermark 可以帮助系统判断:
哪些数据已经“基本到齐”。
这样就可以正确处理:
- 延迟数据
- 窗口计算
- 时间聚合
Flink 的核心设计思想
Flink 的设计有几个非常重要的理念。
1 Stream First
Flink 的核心理念是:
一切都是流。
批处理只是:
有限数据流。
因此:
Flink 的 Batch 和 Stream 使用同一套引擎。
State Driven
Flink 是一个 状态驱动计算系统。
所有计算都围绕状态展开。
例如:
- 用户行为统计
- 实时聚合
- 实时监控
这些都依赖状态管理。
Exactly Once
Flink 非常强调:
数据处理的正确性。
通过:
- Checkpoint
- 分布式快照
- 两阶段提交
Flink 可以实现:
Exactly Once 语义。
这是很多实时系统非常关键的能力。
Flink 在实际系统中的应用
Flink 在很多互联网公司都有大量应用。
典型场景包括:
实时推荐系统
用户行为分析
广告点击统计
实时风控系统
日志实时分析
例如:
用户行为 → Kafka → Flink → ClickHouseFlink 在中间负责:
- 数据清洗
- 实时计算
- 实时聚合