一级二级缓存设计
为什么需要多级缓存
在互联网系统中,随着业务规模不断增长,数据库往往会成为系统的性能瓶颈。大量请求如果直接访问数据库,不仅会带来高延迟,还会导致数据库压力过大,甚至出现连接耗尽、查询变慢等问题。因此,几乎所有高并发系统都会引入 缓存(Cache) 来提升系统性能。
最常见的缓存方式是使用 Redis 作为统一缓存层。客户端请求首先访问 Redis,如果缓存命中,就直接返回数据;如果缓存未命中,再访问数据库并将结果写入缓存。这种方式已经能够显著降低数据库压力。
但随着系统规模继续扩大,仅仅依赖 Redis 仍然可能出现新的问题。例如在高 QPS 场景下,大量请求同时访问 Redis,会产生网络开销和 Redis CPU 压力。同时,某些热点数据可能会被频繁读取,每次都经过网络访问 Redis,也会带来额外延迟。
为了解决这些问题,很多大型系统会引入 多级缓存架构(Multi-Level Cache),其中最常见的一种模式就是 一级缓存 + 二级缓存设计。
一级二级缓存的基本架构
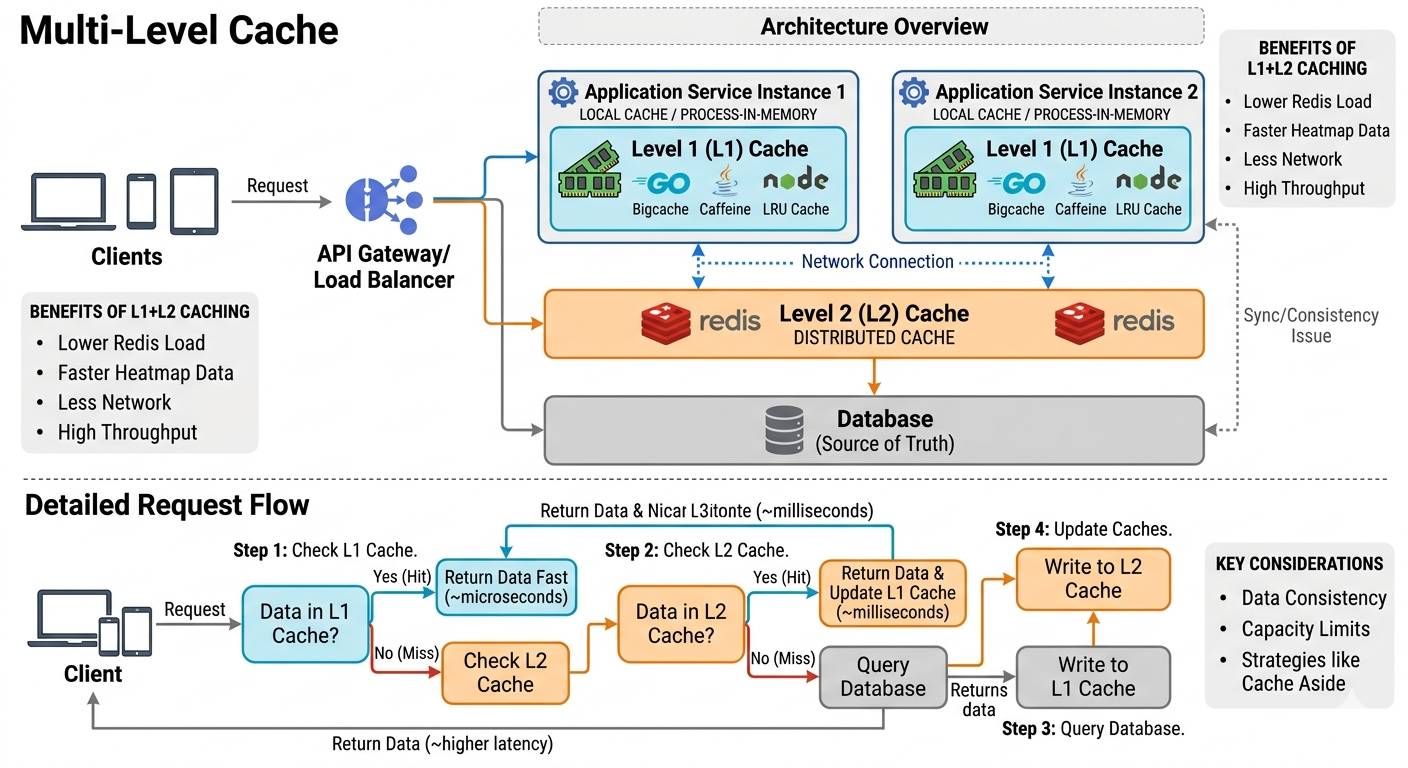
一级二级缓存本质上是一种 缓存分层架构。
通常系统会设计两层缓存:
一级缓存(L1 Cache)
一级缓存通常位于 应用进程内部,也称为 本地缓存(Local Cache)。例如使用:
- Go:bigcache / ristretto
- Java:Caffeine / Guava Cache
- Node:LRU Cache
一级缓存的特点是:
- 访问速度极快(内存访问)
- 不需要网络通信
- 每个服务实例都有自己的缓存
二级缓存(L2 Cache)
二级缓存通常是 分布式缓存系统,最常见的是 Redis 或 Memcached。所有服务实例共享同一个缓存系统。
二级缓存的特点是:
- 多节点共享
- 数据一致性更好
- 容量更大
- 支持分布式部署
整个系统的访问流程通常是:
客户端请求
→ 服务进程
→ 查询一级缓存
→ 未命中则查询二级缓存
→ 再未命中则查询数据库
一级二级缓存访问流程
在实际系统中,一次请求的典型访问流程如下:
首先,请求进入应用服务。系统会优先查询 一级缓存。如果数据存在,直接返回结果,这种情况延迟最低,通常只需要微秒级时间。
如果一级缓存未命中,则继续查询 二级缓存(Redis)。如果 Redis 中存在数据,则返回结果,并将该数据写入一级缓存,以便后续请求可以直接命中本地缓存。
如果 Redis 中也没有数据,则说明缓存未命中,此时系统需要访问数据库。数据库返回结果后,系统会同时写入 Redis 和一级缓存,从而建立新的缓存数据。
整个流程可以理解为:
L1 Cache → L2 Cache → Database
通过这种方式,大部分请求都可以在缓存层被拦截,从而避免频繁访问数据库。
为什么要设计两级缓存
一级缓存和二级缓存各自解决不同的问题,两者结合可以大幅提升系统性能。
降低 Redis 压力
在高并发系统中,如果所有请求都访问 Redis,Redis 可能成为新的瓶颈。通过一级缓存,大量热点数据可以直接在应用内存中返回,从而减少 Redis 请求数量。
减少网络开销
访问 Redis 需要网络通信,即使延迟只有 1ms,在高 QPS 场景下也会产生明显开销。而一级缓存是进程内访问,速度远远快于网络调用。
提升系统吞吐量
通过一级缓存,系统可以处理更多请求,而不会增加 Redis 或数据库负载。
提升热点数据访问效率
在很多业务场景中,少量热点数据会被频繁访问,例如:
- 热门商品
- 用户信息
- 配置数据
- 推荐结果
一级缓存可以让这些热点数据直接在本地命中。
一级缓存设计需要注意的问题
虽然一级缓存性能很好,但它也会带来一些新的问题。
首先是 数据一致性问题。由于一级缓存存在于每个服务实例中,不同实例的缓存数据可能不同步。当数据更新时,如果没有正确的缓存失效机制,可能会导致读取到旧数据。
为了解决这个问题,通常会采用 缓存失效策略。例如在数据更新时,通过消息队列或发布订阅机制通知所有服务实例清除本地缓存。
第二个问题是 缓存容量控制。一级缓存存在于应用内存中,如果缓存数据过多,可能会占用大量内存,影响系统稳定性。因此通常会使用 LRU 或 LFU 等策略限制缓存大小。
第三个问题是 缓存穿透和缓存击穿。当大量请求同时访问不存在的数据,可能会直接冲击数据库。通常可以通过布隆过滤器或互斥锁机制进行防护。
缓存更新策略设计
在多级缓存系统中,缓存更新策略非常关键。
常见策略包括:
Cache Aside(旁路缓存)
应用程序先查询缓存,如果未命中再查询数据库,然后写入缓存。这是最常见的一种模式。
Write Through(写穿透)
应用在写入数据库的同时也更新缓存,保证缓存和数据库数据同步。
Write Back(写回缓存)
应用只写缓存,由缓存系统异步写入数据库。这种方式性能更高,但实现复杂。
在互联网系统中,大多数业务都会采用 Cache Aside 模式,因为它实现简单且稳定。
一级二级缓存架构适用场景
多级缓存架构通常适用于以下场景:
高并发读取系统
例如商品详情页、用户信息查询、配置读取等。
热点数据访问频繁
例如排行榜、推荐列表等。
数据库压力较大
通过缓存层可以显著减少数据库查询次数。
对于一些实时一致性要求非常高的系统,例如金融交易系统,通常不会使用多级缓存,而是直接访问数据库。